First & Second Generation P2P Networks: Napster and Gnutella
The Problem: Everyone wants the music, nobody wants to pay
It's 1999. You want to download a song. Your options? Buy the whole CD for $18 or find it somehow on the internet. But files are hosted on central servers — if the server goes down, or the music label sues it, the file disappears. One point of failure, one lawsuit, game over.
The root cause is simple: centralized servers are a single point of control and failure.
So what if... we made everyone the server?
First Generation: Napster (1999)
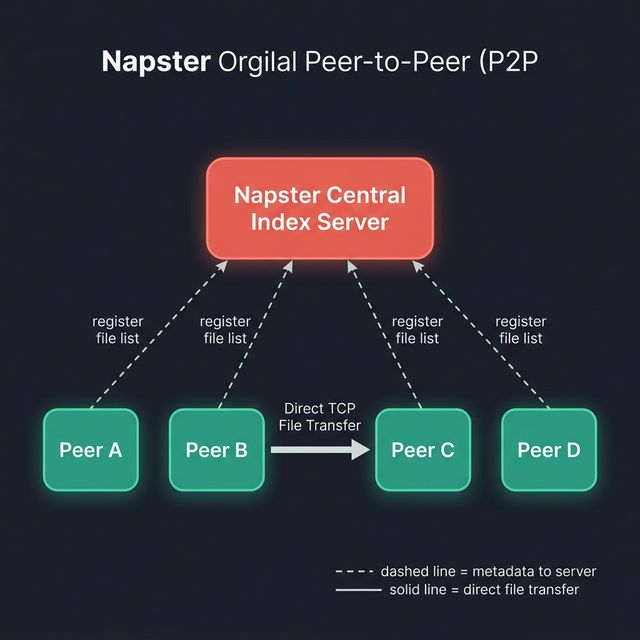
Napster's big idea was peer-to-peer file sharing — your computer connects directly to my computer to get the file. No middleman hosting the data.
But Napster wasn't fully decentralized. It used a hybrid model.
Protocol: Napster Protocol (proprietary, over TCP)
- Every user connected to Napster's central index server
- Your client told the server: "I have these MP3s"
- When you searched, the central server found who had the file
- Then your client connected directly to that peer via TCP to download
Think of it like a phonebook (centralized) but the actual phone calls happen directly between people.
Architecture Diagram
The Fatal Flaw
The phonebook is still owned by Napster. The RIAA sued, the index server got shut down in 2001, and Napster died overnight — because without the central index, nobody could find anybody.
Second Generation: Gnutella (2000)
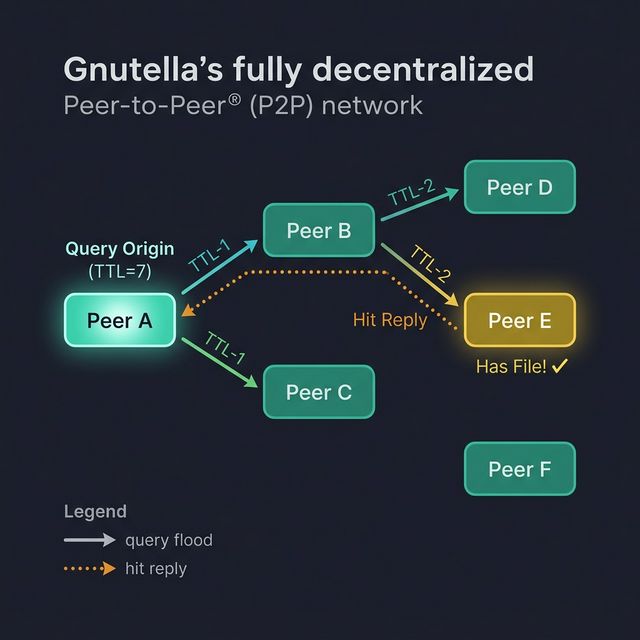
After watching Napster fall, developers thought: what if there's no central server at all? Every peer is equal. No index. No phonebook. Pure anarchy.
Protocol: Gnutella Protocol (open, over TCP)
Gnutella used a fully decentralized, flooding-based model:
- You connect to a few known peers (called bootstrap nodes)
- When you search for a file, your query floods outward — your peers forward it to their peers, and so on
- Each message has a TTL (Time To Live) — it hops at most 7 times before dying, so the flood doesn't consume the entire internet
- When a peer that has the file receives the query, it sends a hit message back along the same path
- You then connect directly to that peer to download
It's like shouting in a crowd — "Does anyone have this song?" — and waiting for someone nearby to shout back.
Architecture Diagram
The Catch
Flooding is expensive. Every search spams the whole network. Gnutella struggled to scale because popular queries generated massive traffic. Later versions introduced ultrapeers (more capable peers that took on routing duties) to fix this — slightly resembling Napster's hierarchy again, ironically.
Side-by-side Comparison
| Napster | Gnutella | |
|---|---|---|
| Generation | 1st | 2nd |
| Architecture | Hybrid (central index + P2P transfer) | Fully decentralized |
| Protocol | Proprietary Napster protocol / TCP | Gnutella protocol / TCP |
| Search | Central server lookup | Flooding with TTL |
| Failure point | Central index server | None — but scales poorly |
| Killed by | Lawsuit (server taken down) | Survived, but replaced by better designs |
The Takeaway
Napster solved the distribution problem but left a legal target wide open. Gnutella solved the centralization problem but created a scalability problem. Each generation learned from the last — and this arms race between resilience and efficiency led to the much smarter designs that followed (BitTorrent, DHT-based networks), but that's a story for another post.